6 minutes
Micro-Services deployment as Snapshots
In this article you’ll learn how we bundle our Micro-Services in Snapshots, targeting deployment in Kubernetes.
Micro-Services
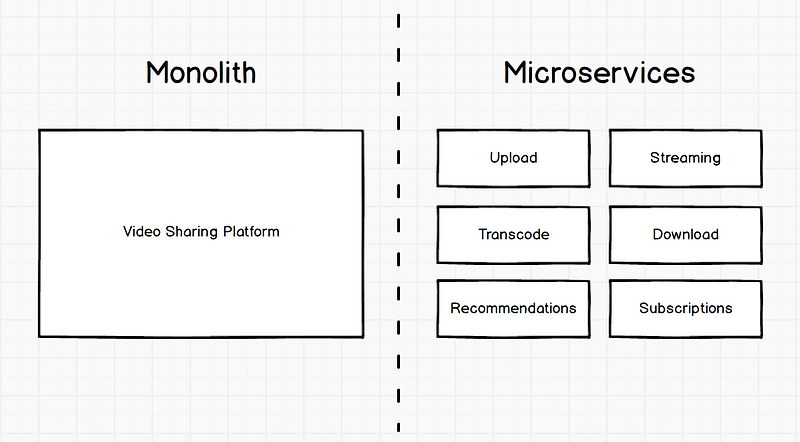
Now we have cut our old monolith into a lot of small micro-services, we need to deploy them.
You think, well, your CI build the micro-service when someone commit a change, and your CD deploy it.
Yeah.
When your project start growing, you end up with a lot of micro-services. If you’re lucky and smart enough, your services API will not change, AT ALL, and all your micro-services are back and forth compatible with each others.
If you live in a real world and iterate often, you’ll end up with API breaking changes between versions, and need to control micro-services deployments.
Sementic Versioning
Semver is really cool as it allows ordering of your releases with increasing numbers, and an easy way to see what could work together (patch or minor update) and what is a breaking change (major update).
Now you have two options :
- all your micro-services use the same version number
- each micro-service follows it’s own version
In the first case, you have to increase the version of ALL micro-services every time someone commit/merge one micro-service.
It can be almost easy if you’re in a mono-repo, but still requires a lot of interactions/coordination between your teams if they all work on different part of micro-services. Not realistic.
In the later, each micro-service have it’s own numbers, and you need to track which version can work with the other. One way to do this is assume that one MAJOR version number means compatibility.
So service A at version 1.2.3 is compatible with service B at version 1.5.4, but not with service C at version 2.2.9
Obviously you can compose with the two… like each micro-service increase its Patch and Minor version on it’s own, and Major version is increased once for all micro-services.
Whatever you do, it can get really hard to track and manage. Most of the time it’s a limitation :
- overhead for building a release
- slow iterations tied to releases
backward compatibility
The graal here is backward compatibility and Feature Flags. This means all of your micro-services can work with any version of your API.
Thanks to some API protocols, like GRPC, it’s free. Add a new field in a protobuf in service A, it will still be able to talk to service B, which will ignore the new field.
But even with GRPC, you sometimes make breaking changes. That’s where enters Feature Sets.
By using a well designed, humm, let’s say, Framework, you can enable/disable features in your micro-services.
So, you added a new feature to your Cart Service so it can call a Taxe Service to give the final price all included. But you can’t use it until all your Taxe services are deployed and tested.
Well, just deploy your new Cart Service, with the Taxe call disabled.
Once you’ve deployed the Taxe Service, you’ll tell your Cart Service to call for it, either by re-starting it with the option, or by calling an internal admin API on all of your Cart micro-services.
Something like Flipt or Unleash could be of some help for that.
This will not solve your versioning problem but could help living-with-it easier.
Releases
So, you’re using some sort of Agile management, SCRUM, you define a target, do your sprint and release something.
but what is a release in micro-services architectures ?
Maybe your sprint only focused on 2 or 3 services, out of the 100’s you may have, because your fraud detection is not in par with your billing workflow, or you only revamped your customer care.
Do you release just these 3 micro-services or do you package and re-deploy all of them ?
Snapshots
Here’s one definitions of what a snapshot it that fits our use-case :
an impression or view of something brief or transitory
You have a bunch of micro-services, each with its own version, and no way to track which one work with the other.
As you constantly iterate over them, versions piles up.
At some point, you take a snapshot and consider that your Release.
That’s what we did lately.
 Example snapshot
Example snapshot
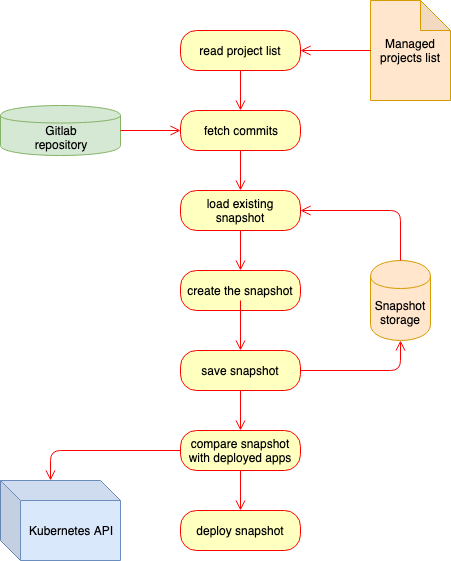
We build an admin tool using VueJs + Vuetify and a Go backend app to manage our snapshots.
The worflow is now :
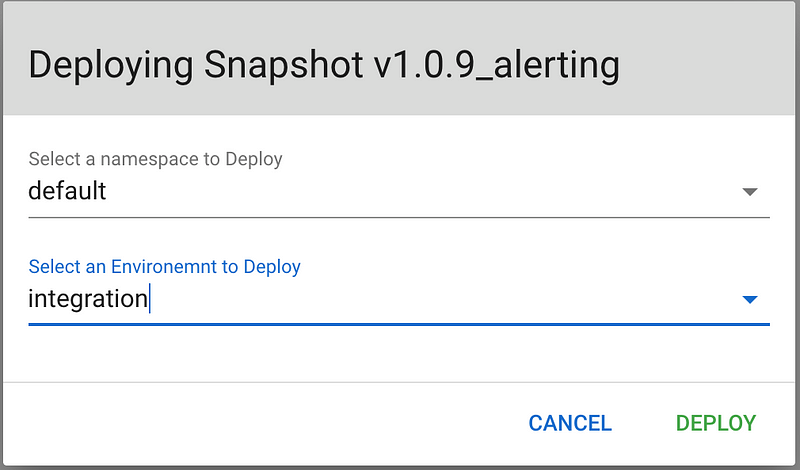
During the deployment process you can select which variable sets you want to use, like dev, integration, prod…
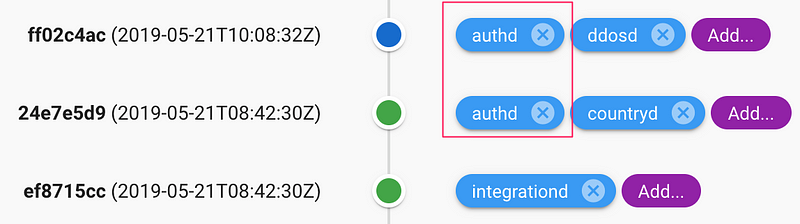
All this gives us the flexibility to deploy many time the same micro-service with different commit versions, like :
All this finally translate to JSON to be stored, for the moment, in a Git repository :
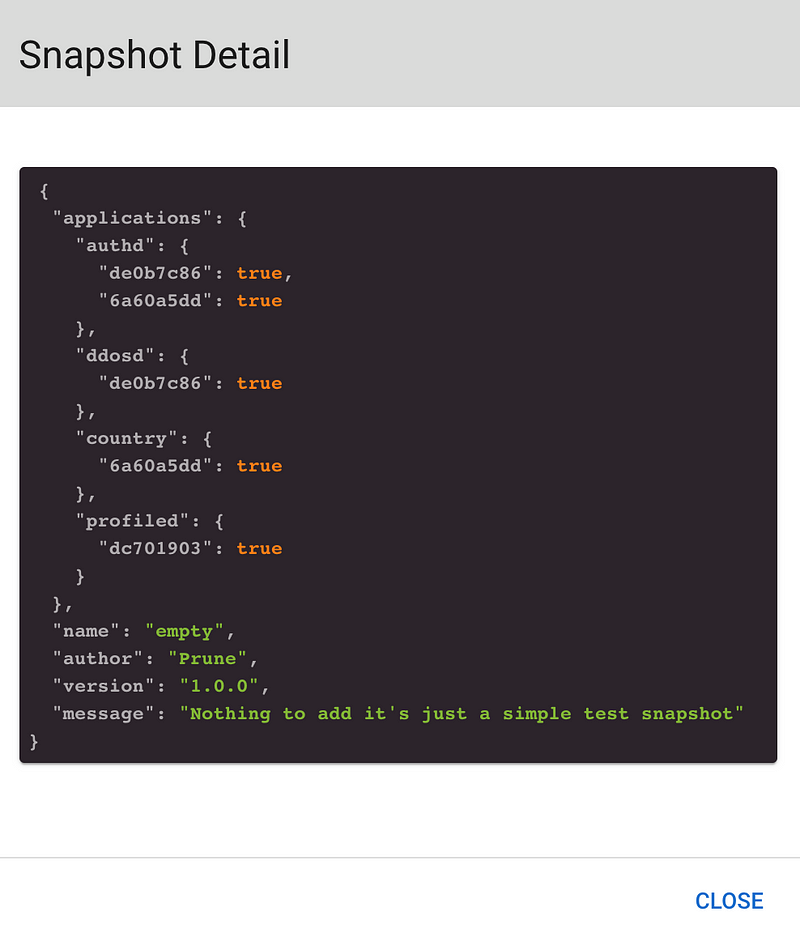
Another tab of the application allows to compare our snapshot with one Kubernetes Namespace pods/deployments, so we can check what the changes will be when we deploy. Here, the deployed Tower micro-service (in orange) is newer than the one selected in the snapshot (in blue) :
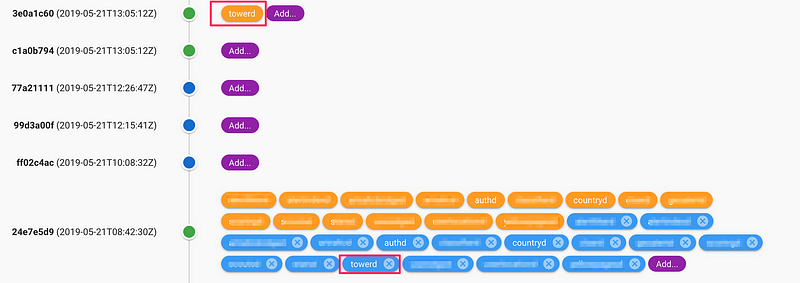
As this imply, we don’t version our micro-services. We use the Git Commit Hash as the version. The PRO of doing this is that we don’t maintain the versions and we use the full commit tree and commit message as a reference of what was done. The CONS is that Commit Hash are not ordered by time, so you need to refer to the commit tree to know if this version is “older” than the other one.
Closing
I know some will complain that it’s too much, and you can do without it, or that Jenkins X would allow better than that.
Let me recap what this tool allows us to do :
- no version to maintain between micro-services
- Devs can work on code, commit things, deploy in the dev environment and create a snapshot with the latest working versions
- QA can deploy this snapshot and test it, maybe modifying it
- Prod people can take the final snapshot and deploy it to prod, pre-prod
- the snapshot IS the delivery, not the code
- we can do A/B testing or canary out of the box (we plan to add Istio Destination Rule management inside the tool)
- you can display/share the snapshot to all your teams so they all work on the same base
- the snapshot is a reference that can be used automatically/programmatically to deploy known versions together. Instead of triggering the perf test for every commits, we can only tests when a snapshot is created. We can then compare snapshots performance metrics of features to get great insight.
I don’t know if this will fill all our needs in the future, but it’s certainly speeding up our devs work and allow us to ensure we’re talking about the same thing when “it’s not working”.
As a side, building this application was the occasion to put some new devs skills in practice, which I hope to improve in the future.
If you ask, No, this app is not released and is not opensource, for now. A lot of things are linked to our infrastructure and it will be a hell to change it to ensure it fits everyone’s.
As an example, we are using Gitlab and it’s Docker registry, and our code is in a mono-repo.
This gives us shortcuts which may not apply to all of you.
Changing from Gitlab to Github would require to re-write most of the code as Github does not have the same API.
Sorry, for now…