10 minutes
BanzaiCloud Kafka Operator tour
Welcome to the Kafka Operator (Magical) Mystery tour !
I’m sure the Beatles would have rebranded the song if they were still here to see how BanzaiCloud team finally rocked the Kafka Operator world !
They also did a good job of branding it, so I won’t dive into “why this another Kafka Operator is better than the others”. I can assure it is !
Just check :
- https://banzaicloud.com/products/kafka-operator/
- https://banzaicloud.com/blog/kafka-operator/
- https://github.com/banzaicloud/kafka-operator
EDIT : also check my other article for Kafka cluster autoscaling
Overview
Few days ago BanzaiCloud released the 0.6.x version of the Operator, with :
- rolling updates
- Topic management
- User management
I think the operator is now on par with all others in term of features, not counting everything it’s adding to it.
New release, new API, lots of changes… things break during Upgrade :)
I just want to quickly post how to build your config (with example) to help you bootstrap your cluster quickly.
It is also great to get a look at the sample config found in the Git repo : https://raw.githubusercontent.com/banzaicloud/kafka-operator/master/config/samples/banzaicloud_v1beta1_kafkacluster.yaml
Note that I’m not part of BanzaiCloud and I don’t get any advantage whatsoever by publishing this post.
Kafka Operator
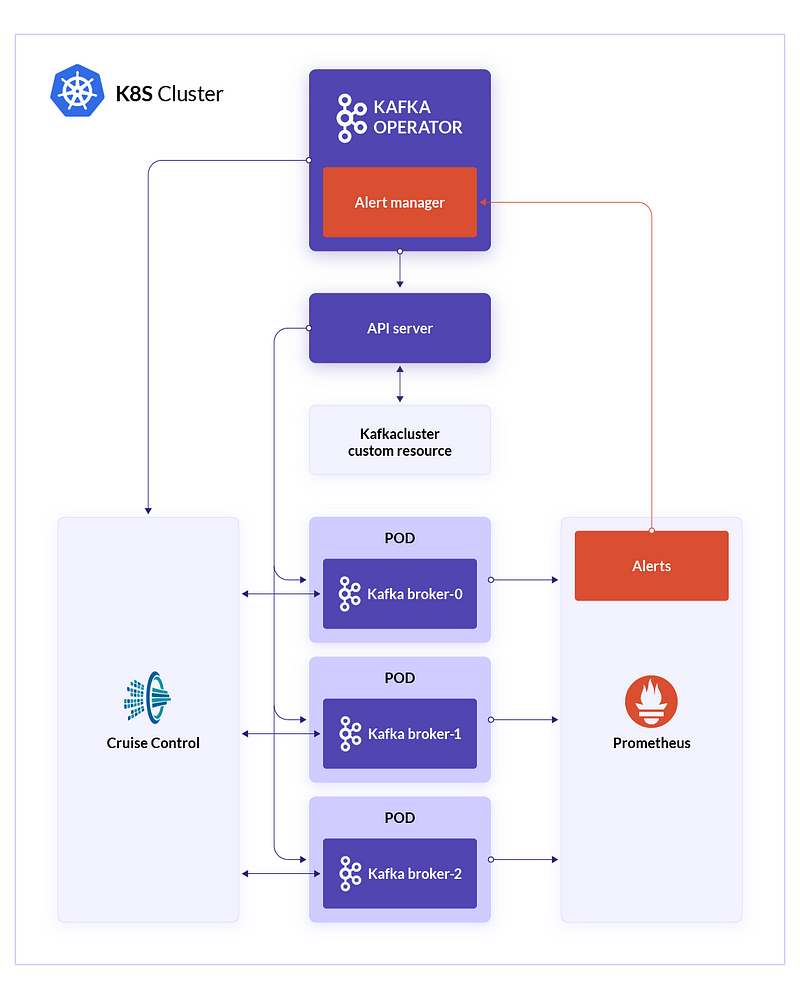
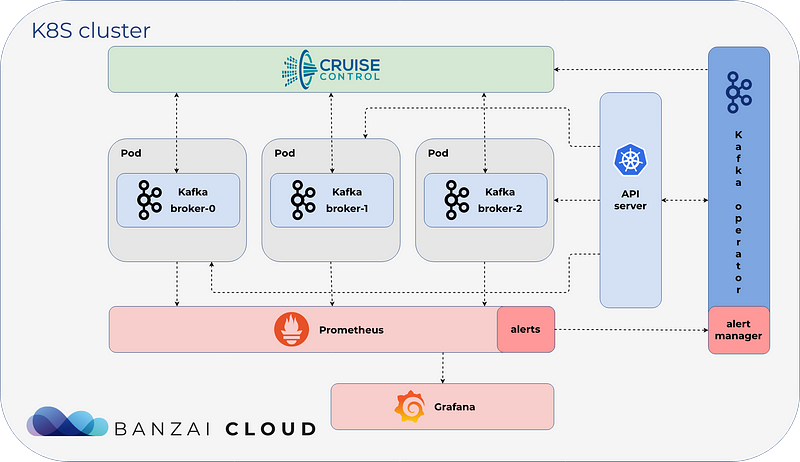
Operator talks to the API server and watch for kafkacluster Resource. It also talks to CruiseControl, a Java application from Linkedin which is “a general-purpose system that continually monitors our clusters and automatically adjusts the resources allocated to them to meet pre-defined performance goals”. Finally it “talks to” Prometheus, watch for alerts and take actions.
BanzaiCloud provides a Helm Chart (as too many others out there), so let’s use it. As I don’t use Tiller, I just usehelm template:
git clone https://github.com/banzaicloud/kafka-operator.git
cd kafka-operator
helm template charts/kafka-operator \
--set fullnameOverride=kafka \
--set prometheus.enabled=false \
--set prometheusMetrics.authProxy.enabled=false \
--set operator.image.repository="< private repo >/kafka-operator" \
--set operator.image.tag="0.6.1" \
--set prometheus.server.configMapOverrideName="" \
--set imagePullSecrets={docker-images-registry-secret} \
--namespace tools > charts/kafka-operator/generated.yaml
kubectl apply -n tools charts/kafka-operator/generated.yaml
You should have a running kafka operator now. Check using kubectl :
kubectl -n tools get pods
NAME READY STATUS RESTARTS AGE
kafka-operator-85b894b8c4-wjmt7 1/1 Running 0 28m
Note : I wasn’t able to upgrade from 0.5 to 0.6 version. The CRD namespace switched from kafkaclusters.banzaicloud.banzaicloud.io to kafkaclusters.kafka.banzaicloud.io.
Also, when deleting the old deployment I saw my Kafka pods deleted, removing the cluster once and for all.
In theory, it SHOULD have worked… a bit… It should have grow my cluster to a 6 node cluster, sync, and I should have been able to remove the old one.
Note 2 : There was a bug in 0.6.0 (corrected in 0.6.1, I haven’t tested though) where you HAD to use Kafka Brokers ID starting at 0 (0, 1 and 2 for a 3 node cluster)
My best guess was to destroy everything. If I was on a prod system, I think I would have backuped my data, rebuild a new cluster then re-import the data.#### Destroying everything
Delete your Operator deployment : kubectl -n tools delete deployment kafka-operator
This should take care of all the pods, PVC… you may have to manually delete your PVs.
Then delete everything in Zookeeper. This is needed if you change Kafka version or Broker IDs. Do not do this on Production !!
kubectl exec -ti zk-zookeeper-0 bin/zkCli.sh
deleteall /admin
deleteall /brokers
deleteall /cluster
deleteall /config
deleteall /consumers
deleteall /controller_epoch
deleteall /isr_change_notification
deleteall /kafka-manager
deleteall /latest_producer_id_block
deleteall /log_dir_event_notification
KafkaCluster
The KafkaCluster CRD have changed A LOT from 0.5.x to 0.6.x.
So much that it’s not compatible AT ALL !
I’m not going to point out the changes. Most of you don’t have a 0.5 running, so just start with a 0.6 spec.
I’m going to break down in may parts as it’s quite a huge spec…
This is for a 3 nodes cluster named kf-kafka, using Zookeeper on port 2181 in the same namespace (alerting).
Global spec
apiVersion: kafka.banzaicloud.io/v1beta1
kind: KafkaCluster
metadata:
labels:
controller-tools.k8s.io: "1.0"
kafka_cr: kf-kafka
name: kf-kafka
namespace: alerting
spec:
headlessServiceEnabled: false
zkAddresses:
- "zk-zookeeper:2181"
rackAwareness:
labels:
- "failure-domain.beta.kubernetes.io/region"
- "failure-domain.beta.kubernetes.io/zone"
oneBrokerPerNode: false
clusterImage: "your-own-repo/kafka:2.3.0.7"
rollingUpgradeConfig:
failureThreshold: 1
headlessServiceEnabled tells to create a headless service for Kafka brokers discovery. This is the “old fashion” way, as other Operators or Helm charts do. It’s a service without any IP, where the DNS is configured to give you all the names of the pods that are part of the service selector.
Ex with my old cluster :
nslookup kf-broker-kafka
Name: kf-broker-kafka
Address 1: 10.2.128.124 kf-kafka-1.kf-broker-kafka.alerting.svc.cluster.local
Address 2: 10.2.128.254 kf-kafka-0.kf-broker-kafka.alerting.svc.cluster.local
Address 3: 10.2.129.225 kf-kafka-2.kf-broker-kafka.alerting.svc.cluster.local
Setting it to False will not create the Headless Service. You don’t usually need it so set it to False.
With the Operator, you will end up with two services :
- -all-broker (kf-kafka-all-broker) : a ClusterIP service which point to all your cluster Instances. You can use it to bootstrap your clients.
- - (kf-kafka-0, kf-kafka-1, kf-kafka-2) : one service per Broker. This is used internally by Kafka Brokers to talk to each other, or if you want to give the full list of brokers when bootstrapping.
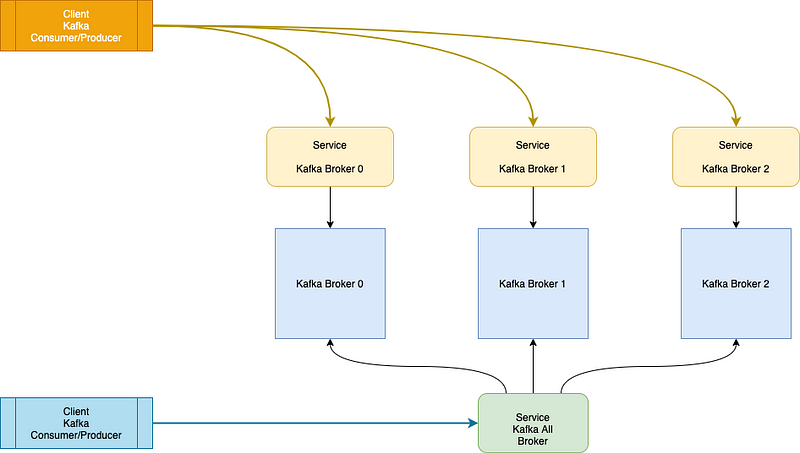
oneBrokerPerNode, when enabled, will put one broker on each node, NOT MORE. Meaning if you have a 2 node cluster and create a 3 broker Kafka cluster, one of the brokers will NEVER be scheduled.
While it’s a good option to set to ensure reliability of the cluster, you may end up with unschedulable brokers, and a broken cluster. It’s sometimes better to have two brokers on the same node instead of a broken cluster… Affinity is also set on the pods by default, so Kubernetes should be able to handle it himself. Keep this option to False.
rollingUpgradeConfig tels how many brokers can be broken at a time… another way of seeing it is “how many brokers I can rolling upgrade in parallel”. Keep it to 1 for a 3 node cluster, and increase it depending on your broker count and replication factor.
brokerConfigGroups
brokerConfigGroups:
# Specify desired group name (eg., 'default_group')
default_group:
# all the brokerConfig settings are available here
serviceAccountName: "kf-kafka"
imagePullSecrets:
- name: docker-images-registry
kafkaJvmPerfOpts: "-server -XX:+UseG1GC -XX:MaxGCPauseMillis=20 -XX:InitiatingHeapOccupancyPercent=35 -XX:+ExplicitGCInvokesConcurrent -Djava.awt.headless=true -Dsun.net.inetaddr.ttl=60 -Dcom.sun.management.jmxremote -Dcom.sun.management.jmxremote.authenticate=false -Dcom.sun.management.jmxremote.ssl=false -Djava.rmi.server.hostname=${HOSTNAME} -Dcom.sun.management.jmxremote.rmi.port=9099"
storageConfigs:
- mountPath: "/kafka-logs"
pvcSpec:
accessModes:
- ReadWriteOnce
storageClassName: ssd
resources:
requests:
storage: 30Gi
This is a way to configure some Broker config templates that you will use to create your brokers. The broker config (see later) will have precedence on what is defined here. See it as some defaults so your broker definition is smaller :)
Brokers
brokers:
- id: 0
brokerConfigGroup: "default_group"
brokerConfig:
resourceRequirements:
limits:
memory: "3Gi"
requests:
cpu: "0.3"
memory: "512Mi"
- id: 1
brokerConfigGroup: "default_group"
brokerConfig:
resourceRequirements:
limits:
memory: "3Gi"
requests:
cpu: "0.3"
memory: "512Mi"
- id: 2
brokerConfigGroup: "default_group"
brokerConfig:
resourceRequirements:
limits:
memory: "3Gi"
requests:
cpu: "0.3"
memory: "512Mi"
Thanks to the BrokerConfigGroup, this part is really light.
I kept the resources defined in each Broker so I can tune them up… while I see no reasons to have them not being the same for most people…
You can see I did NOT set limits.cpu parameter… this is due to the CFS Quota bug that is not patched on Azure, which will Throttle some of your pods even if they don’t use any CPU…
Config
#clusterWideConfig: |
# background.threads=2
readOnlyConfig: |
offsets.topic.replication.factor=2
default.replication.factor=2
transaction.state.log.min.isr=1
log.dirs=/kafka-logs/data
delete.topic.enable=true
num.partitions=32
auto.create.topics.enable=false
transaction.state.log.replication.factor=2
You now have to set your config parameters in different components. This is due to the Rolling Upgrade feature : the operator needs to know between a change in read-only options (which require a node restart) and user options.
You can read more here : https://kafka.apache.org/documentation/#dynamicbrokerconfigs
Listeners
listenersConfig:
internalListeners:
- type: "plaintext"
name: "plaintext"
containerPort: 9092
usedForInnerBrokerCommunication: true
Nothing to tell here… you will have a lot more stuff here if you use SSL…
CruiseControl
cruiseControlConfig:
image: "solsson/kafka-cruise-control:latest"
serviceAccountName: "kf-kafka"
config: |
...
capacityConfig: |
{
"brokerCapacities":[
{
"brokerId": "-1",
"capacity": {
"DISK": "200000",
"CPU": "100",
"NW_IN": "50000",
"NW_OUT": "50000"
},
"doc": "This is the default capacity. Capacity unit used for disk is in MB, cpu is in percentage, network throughput is in KB."
}
]
}
clusterConfigs: |
{
"min.insync.replicas": 2
}
Again, not much difficulties here… Define your own Broker Capacities, specifically the DISK parameter if your cluster use a larger disk than the small default, this will help CC (CruiseControl) to build it’s alarms.
the “…” is a LONG list of options… I kept the defaults for now.
Monitoring
monitoringConfig:
# jmxImage describes the used prometheus jmx exporter agent container
jmxImage: "banzaicloud/jmx-javaagent:0.12.0"
# pathToJar describes the path to the jar file in the given image
pathToJar: "/opt/jmx_exporter/jmx_prometheus_javaagent-0.12.0.jar"
# kafkaJMXExporterConfig describes jmx exporter config for Kafka
kafkaJMXExporterConfig: |
lowercaseOutputName: true
rules:
This is used to add the needed jars and set up the JMX Exporter for Prometheus. Add your own rules or leave the defaults…
Now you should have a perfect Kafka Cluster running !!
You can see my full config here.
Kafka Topics
This is a new addition to this Operator. You can now upload some kafkatopic manifests and create / delete topics.
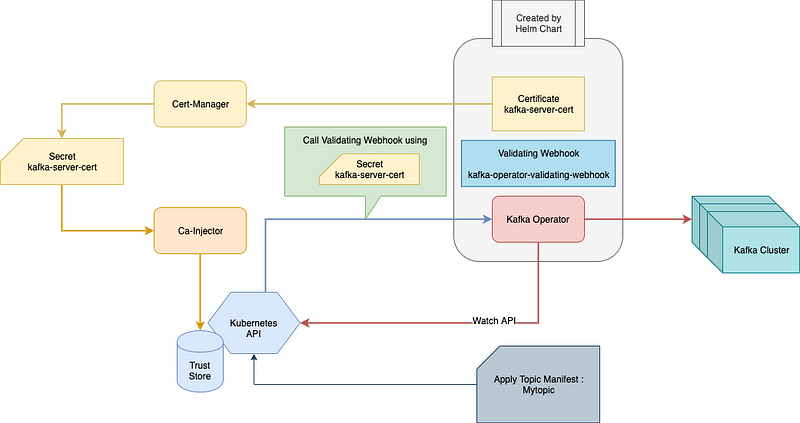
As of 0.6.0 / 0.6.1, this feature use a Kubernates Validating Webhook to ensure the manifest is well formated. For that to work, two other pieces have to be installed in your cluster : Cert-Manager and CAInjecter (both from the Cert-Manager project from JetStack).
Cert-Manager will create an SSL Certificate, and CA-Inject will provide it to the K8s API so it is authorized to call the Kafka Operator Webhook.
Cert-Manager
To install it, if you don’t already have it, use the Helm Chart !! If you are using an old version, re-install. Ca-Injector is a new addition and needs to be installed. Check with :
kubectl get pods -n cert-manager
NAME READY STATUS RESTARTS AGE
cert-manager-c76c4dbfd-nvf4v 1/1 Running 0 20h
cert-manager-cainjector-55f87f5c76-ndhjv 1/1 Running 0 20h
If you need to install :
helm fetch --untar --untardir . jetstack/cert-manager
helm template
--name cert-manager
--set global.imagePullSecrets[0].name=docker-images-registry
--set webhook.enabled=false
--set image.repository="<private repo>/certmanager"
--set image.tag="v0.10.1"
--set cainjector.image.repository="<private repo>/certmanager-cainjector"
--set cainjector.image.tag="v0.10.1"
--set cainjector.enabled="true"
--namespace cert-manager
'./cert-manager' > certmanager-generated.yaml
kubectl apply -n cert-manager -f certmanager-generated.yaml
It’s as simple as that. Of course, you may have tons of problems with Helm, as I usually do… I call it “Hellm”… I’m a hater, or, right :)
You can check the Validating Webhook to ensure it was provided with a valid Certificate :
kubectl get validatingwebhookconfiguration kafka-operator-validating-webhook -o jsonpath="{['webhooks'][0]['clientConfig']['caBundle']}"
LS0tLS1VeryLongStringWithBase64BitOfTheSSLCertificateWhichIRemovedSoItWontMakeThisArticleEvenHardToReadLS0tCg==
KafkaTopic
The final part in the Cluster creations, the topic(s) !
---
apiVersion: kafka.banzaicloud.io/v1alpha1
kind: KafkaTopic
metadata:
name: compactedtopic
namespace: alerting
spec:
clusterRef:
name: kf-kafka
name: compactedtopic
partitions: 8
replicationFactor: 2
config:
segment.bytes: "104857600"
delete.retention.ms: "8640000"
retention.ms: "259200000"
cleanup.policy: "compact"
---
apiVersion: kafka.banzaicloud.io/v1alpha1
kind: KafkaTopic
metadata:
name: regulartopic
namespace: alerting
spec:
clusterRef:
name: kf-kafka
name: regulartopic
partitions: 128
replicationFactor: 2
config:
segment.bytes: "104857600"
delete.retention.ms: "864000"
retention.ms: "259200000"
What you see here is the YAML for 2 topics, one compacted, the other one regular. Topics will be created in the cluster kf-kafka.
It’s pretty straightforward… just apply it…
Note : For now, the Operator can create a topic and delete a topic it manages. If you create a topic then delete it “by hand”, the Operator will log some errors about it.
While this Topic Management is quite new, everything is not yet decided or implemented. I’ve created a PR to track this issue : https://github.com/banzaicloud/kafka-operator/issues/158
Conclusion
This is a long and ugly post, with almost no images, about the BanzaiCloud Kafka Operator. With that you should be able to start using it without the pitfalls I was trapped in.
More docs and more features are coming so I don’t know for how long this post will be relevant. I’ll try to keep up :)
Remember this Operator is still new, at 0.x versions, and that the API may change quite a bit until 1.0 is released. Except that, I’m pretty confident on the stability and I’m about to deploy it everywhere up to production (to replace Strimzi and Statefulsets)!
I want to thank the people on the Slack Channel who helped me through this, Balint and Tinyzimmer (who also added the topic/user management).
I also thank BanzaiCloud team for their work, and, oh, I used some of your pictures from your blog/website to illustrate… hope you don’t mind ?